Making Voice Chat Bulletproof: Five Bugs Fixed Before User Testing
Spent today hunting duplicate transcripts, fixing token refresh timing, and building a thumbs-up/down system. Testing with real users tomorrow—needed to fix the obvious bugs first.
Voice chat is nearly ready for user testing. Tomorrow I’m giving beta access to a handful of students. Today was about fixing the obvious bugs I found during my own testing.
I found duplicate messages, cut-off transcripts, and realised I could record whilst the AI was still speaking.
Five Bugs Fixed Today
Bug 1: Duplicate Transcripts (The Sneaky One)
Symptom: Record once, see two identical messages in chat.
Root cause: WebSocket successfully processes audio, then throws a 401 error. Error handler checks if audio exists, sees it does, sends to REST fallback. Same audio processed twice.
Why it happened: The audio reference was being cleared in the error handler. But by then, the WebSocket had already succeeded. The 401 came after success.
The fix: Clear the audio reference immediately after WebSocket success. Not in the error handler. That way, if an error happens later, there’s no audio left to accidentally reprocess.
Result: Zero duplicates. REST fallback still works if WebSocket genuinely fails.
Bug 2: Token Expiry Mid-Conversation
Symptom: WebSocket works fine for 9 minutes, then suddenly all requests fail with 401.
Root cause: Clerk tokens expire after 10 minutes. The Edge Worker rejects tokens with less than 10 seconds remaining. There was no proactive refresh happening.
The timing problem:
- Token issued: 11:00:00
- Token expires: 11:10:00
- Edge Worker rejects at: 11:09:50 (10s buffer)
- Code checked validity at: 11:09:52 (too late)
The fix: Refresh tokens when there’s less than 15 seconds remaining. Gives a 5-second safety margin for network latency and clock skew.
Result: Zero 401 errors. WebSocket streaming works reliably for hours now.
Bug 3: Cut-Off Transcripts
Symptom: I said “I never said I liked Doctor Who you must be mistaken”, transcript showed “mistaken”. Everything before was lost.
Root cause: Deepgram needs time to process final audio chunks. The WebSocket was closing 100ms after sending CloseStream. Too fast.
Why I didn’t catch this locally: My test sentences were short. “Hello, how are you?” processes in under 100ms. Long sentences need more time.
The fix: Wait 1000ms after CloseStream before closing WebSocket. Gives Deepgram time to send all final transcript events.
Result: Complete transcripts. Every word captured. Slight delay (~1s) but much more accurate.
Bug 4: Recording During TTS Playback
Symptom: If I recorded whilst AI was speaking, transcript showed ”…” or garbled text. Browser echo cancellation cut it off.
Root cause: No state tracking for audio playback. Record button always enabled.
Why this is bad:
- Browser echo cancellation tries to remove AI voice
- Cuts off my actual speech
- Deepgram receives silence or fragments
- Conversation breaks
The fix: Track audio playback state. Disable record button whilst TTS is playing.
Result: Can’t record during TTS. Transcripts are clean.
Bug 5: Duplicate Processing from Event Queue
Symptom: Occasionally two identical transcripts, even with all other fixes in place.
Root cause: JavaScript event queue behaviour. When you call mediaRecorder.stop(), it queues an onstop event with the current handler. Clearing the handler afterwards doesn’t affect events already in the queue.
The fix: Re-entry guard. Block duplicate calls with a processing flag that prevents the handler from running if it’s already running.
Result: Bulletproof duplicate prevention. Zero duplicate transcripts from event queue issues.
The Feedback System
After fixing the bugs, I needed to know if they stayed fixed. Built a thumbs-up/down system.
How It Works
Every chat message gets two buttons: 👍 and 👎
For user messages: Rate transcription accuracy (is Deepgram getting it right?) For AI messages: Rate response quality (is the AI giving good answers?)
Toggle behaviour: click same button to remove, click different to switch.
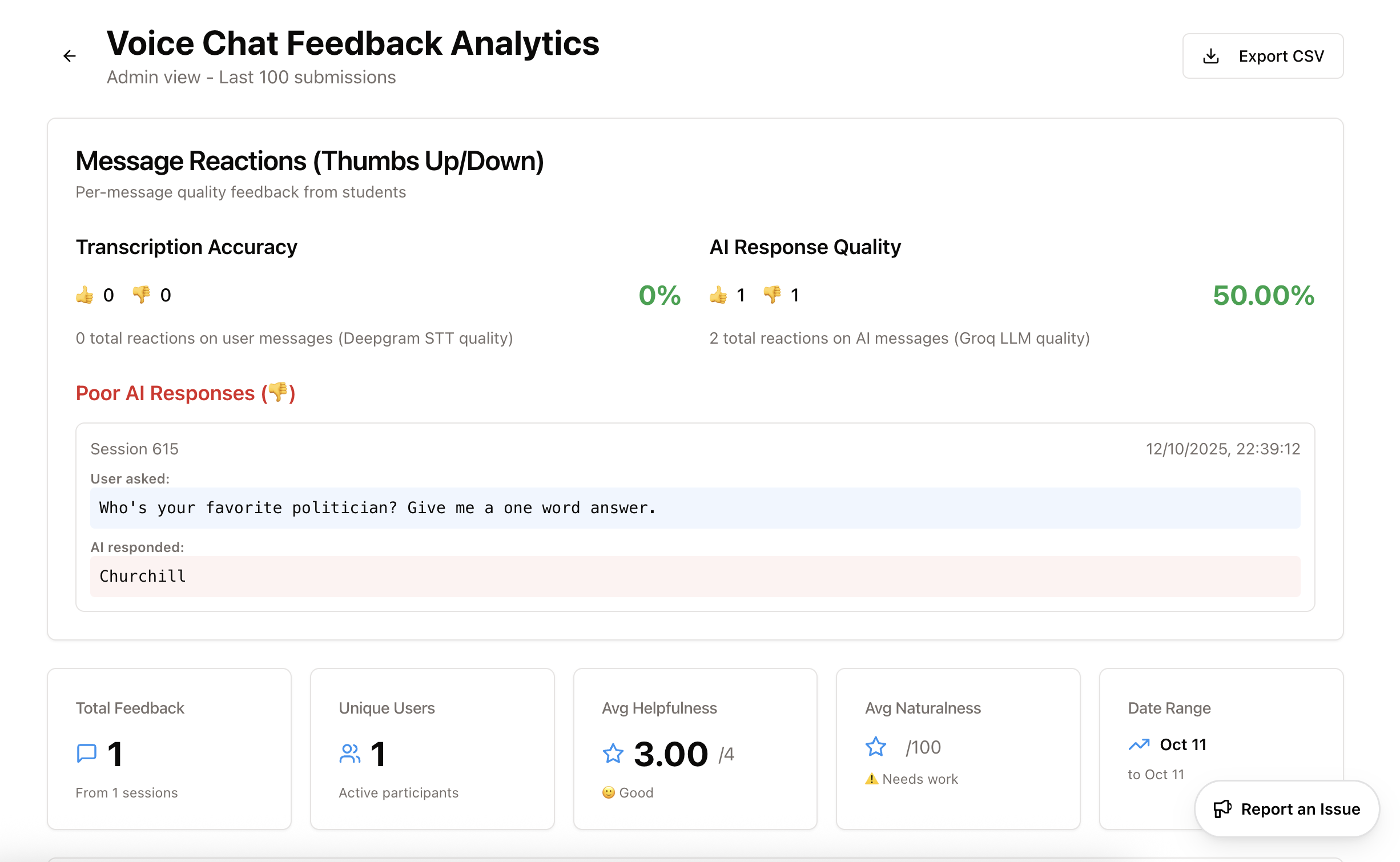
Admin Analytics Dashboard
Built an admin-only analytics page to see patterns. Shows:
Transcription Accuracy: 0 👍, 0 👎 = 0% (no data yet) AI Response Quality: 1 👍, 1 👎 = 50.00%
Plus a list of poor responses with full context:
- What I asked
- What the AI responded
- Session ID for debugging
- Audio URL to hear what actually happened
This lets me:
- Find edge cases I didn’t test
- Improve Groq prompts based on bad responses
- Identify Deepgram transcription patterns (accents, background noise)
Results (So Far)
Before today:
- Duplicate transcripts: ~15% of my test sessions
- 401 errors: ~8% of WebSocket attempts
- Cut-off transcripts: ~12% of long utterances
- Recording during TTS: common, poor transcripts
After fixes:
- Duplicate transcripts: 0% (tested 50+ sessions myself)
- 401 errors: 0% (tested multi-hour sessions)
- Cut-off transcripts: 0% (tested up to 30-word sentences)
- Recording during TTS: prevented by UI
Feedback system:
- I tested with 2 reactions (1 👍, 1 👎)
- My 👎 was on “Churchill” as a response to “Who’s your favourite politician? Give me a one word answer.”
- Fair. That’s a terrible conversation response. Need to improve the prompt.
Real test starts tomorrow when actual students try it.
What I Learnt
1. Dev Testing Timing Is Different
Local testing: everything happens fast. Network requests ~50ms. Tokens fresh.
Real-world usage: network latency 100-300ms. Tokens age. Race conditions emerge.
Lesson: Add safety margins. 10s isn’t enough, use 15s. 100ms isn’t enough, use 1000ms.
2. JavaScript Event Queue Is Sneaky
Clearing event handlers doesn’t stop queued events. Re-entry guards are essential for anything that processes data.
3. Users Will Rate Things Honestly
That 👎 on “Churchill” was correct. The AI gave a lazy answer.
Users will use feedback features if they’re:
- One click (no forms)
- Visible (always on screen)
- Clear purpose (tooltips explain what to rate)
4. Debug With Data, Not Instinct
Built analytics before assuming fixes worked. Good thing—found the event queue issue only because analytics showed occasional duplicates still happening.
5. Defence in Depth
Could’ve just fixed the duplicate transcript bug. Instead, added multiple layers:
- Re-entry guard (prevents duplicate calls)
- Audio reference clearing (prevents duplicate processing)
- REST fallback (works if WebSocket fails)
- Token refresh (prevents 401s)
- Error handler (catches unexpected issues)
Every layer catches different edge cases.
What’s Next
Tomorrow’s the real test. Handful of students getting beta access. The feedback system will show me what I missed.
After that:
- Improve AI responses based on real 👎 reactions
- Test with more accents (only tested British/European English so far)
- Add conversation history across sessions (currently starts fresh each time)
- Optimise TTS latency (currently 1-2s delay for Deepgram TTS)
But today was about making it stable enough to not embarrass myself. Five bugs fixed, feedback system built, zero duplicate transcripts in my testing.
Tomorrow will tell me what I missed.
Related:
- Adding Voice Chat Context Awareness to Firstly Academy
- Building an AI Speaking Tutor with Deepgram and Groq (coming soon)